Introducing Command R+: Our new, most powerful model in the Command R family.

< Back to blog

 Nicholas Frosst, Jay Alammar
Nicholas Frosst, Jay Alammar
Sep 15, 2022
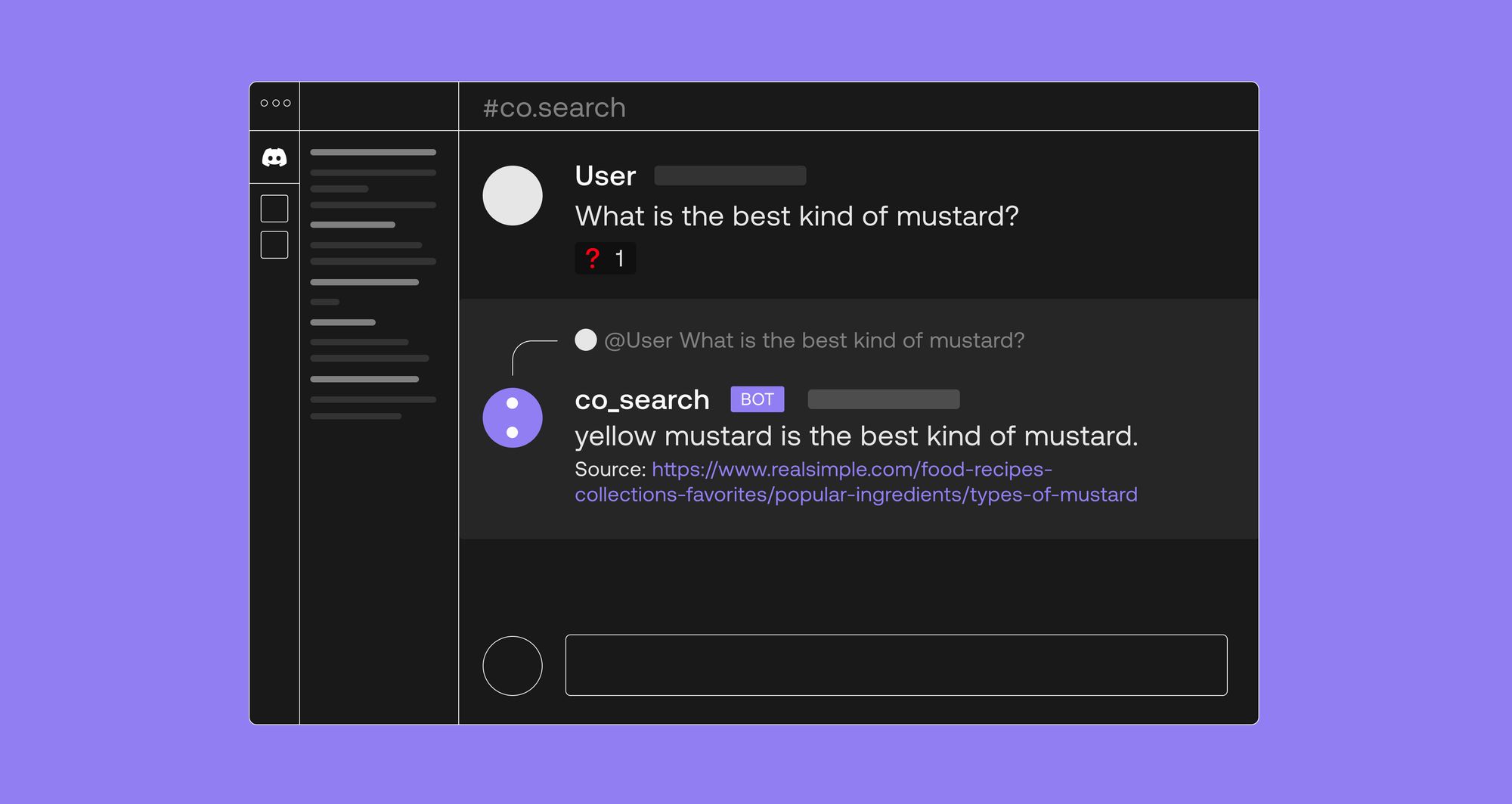
Building a Search-Based Discord Bot with Language Models
Nicholas Frosst, Jay AlammarShare: